Conference45min
UDA (Unified Data Architecture) à Netflix
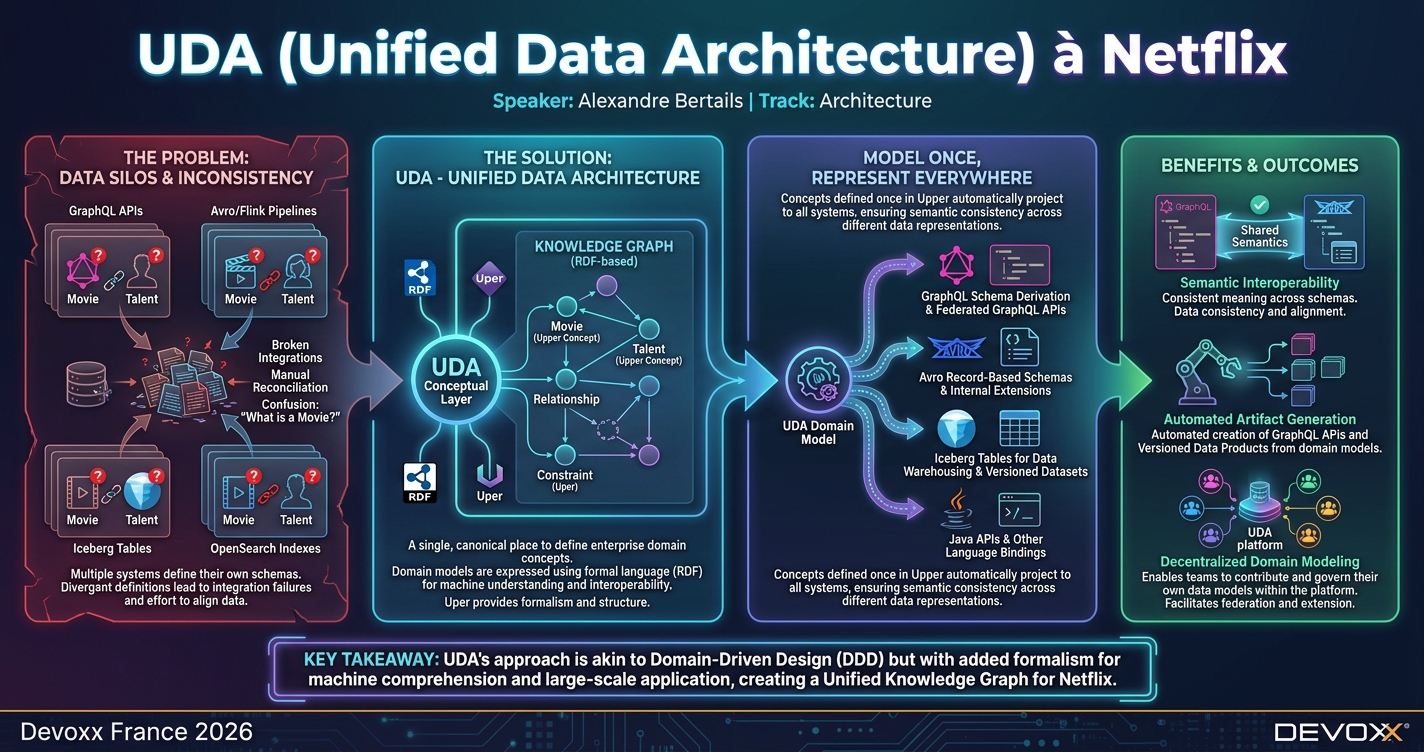
Cette présentation explique comment Netflix unifie ses modèles métier grâce à UDA, un cadre conceptuel unique qui projette automatiquement les définitions vers tous les systèmes (GraphQL, Avro, Iceberg, etc.). Elle aborde la fragmentation des données, l’usage des knowledge graphs RDF et le principe “Model Once, Represent Everywhere”.
talk.summaryAiDisclaimer

Alexandre BertailsNetflix
talkDetail.whenAndWhere
Wednesday, April 22, 15:40-16:25
Amphi bleu
À Netflix, des dizaines de systèmes coexistent : APIs GraphQL, pipelines Avro/Flink, tables Iceberg, indexes OpenSearch… Chaque système définit ses propres schémas, sa propre compréhension de ce qu'est Movie ou Talent. Quand ces définitions divergent — et elles divergent toujours — on le paie en intégrations cassées, en réconciliation manuelle, et en heures passées à répondre à la question : "Quel système a la bonne définition ?"
D'où UDA, un endroit unique et canonique pour définir les concepts métier de l'entreprise. Quand une équipe définit Movie dans notre framework conceptuel Upper, cette définition se projette automatiquement vers tous les systèmes: schémas GraphQL, schémas Avro, tables Iceberg, APIs Java, …
Trois enseignements clés :
D'où UDA, un endroit unique et canonique pour définir les concepts métier de l'entreprise. Quand une équipe définit Movie dans notre framework conceptuel Upper, cette définition se projette automatiquement vers tous les systèmes: schémas GraphQL, schémas Avro, tables Iceberg, APIs Java, …
Trois enseignements clés :
- La fragmentation des données — Comment des modèles déconnectés mènent à la duplication et aux problèmes de qualité, et comment une sémantique partagée reconnecte les silos.
- Les knowledge graphs (graphes de connaissance) — Ce qu'est réellement un knowledge graph et comment Netflix utilise RDF pour structurer ses données.
- Model Once, Represent Everywhere — Comment un concept défini une seule fois se projette vers GraphQL, Avro, SQL, et plus encore.
Alexandre Bertails
Alexandre Bertails est le créateur de Upper, le framework de modélisation de domaines à Netflix, où il est responsable de la couche conceptuelle du graphe de connaissances UDA (Unified Data Architecture). Le principe de UDA est "model once, represent everywhere" : les équipes modélisent leurs domaines dans Upper, puis les projettent automatiquement en schémas GraphQL pour l'Enterprise Gateway, en schémas Avro pour la plateforme Data Mesh, en tables Iceberg pour l'entrepôt de données, et en APIs Java et POJOs pour les services — le tout avec interopérabilité sémantique et gouvernance intégrée. Avant UDA, il a contribué à fédérer la Data Platform de Netflix dans l'Enterprise GraphQL Gateway, où il était l'expert GraphQL de référence.
Il a débuté sa carrière sur SPAR, le système de préservation numérique de la BnF, avant de rejoindre l'équipe systèmes du W3C au MIT — d'abord comme Webmaster, où il a dirigé le développement d'une plateforme unifiée pour les validateurs du W3C, puis comme éditeur du Direct Mapping RDB2RDF, où il a formalisé la dénotation naturelle de SQL vers RDF. Il a été contact du W3C pour le RDB2RDF Working Group, puis pour le LDP Linked Data Platform Working Group, où il a contribué le Linked Data Patch Format. C'est au W3C qu'il a créé Banana RDF, une bibliothèque Scala issue du projet read-write-web mené pour Tim Berners-Lee. Chez Apple, il a déployé le graphe de connaissances marketing et retail d'Apple sur apple.com avec schema.org, avec un impact SEO significatif, et a représenté Apple au sein du Schema.org Community Group. Il a ensuite été data engineer sur la plateforme anti-fraude d'Apple Services, puis a dirigé une équipe d'ingénieurs pour migrer l'infrastructure d'Apple Media Services vers Kubernetes.
Il a débuté sa carrière sur SPAR, le système de préservation numérique de la BnF, avant de rejoindre l'équipe systèmes du W3C au MIT — d'abord comme Webmaster, où il a dirigé le développement d'une plateforme unifiée pour les validateurs du W3C, puis comme éditeur du Direct Mapping RDB2RDF, où il a formalisé la dénotation naturelle de SQL vers RDF. Il a été contact du W3C pour le RDB2RDF Working Group, puis pour le LDP Linked Data Platform Working Group, où il a contribué le Linked Data Patch Format. C'est au W3C qu'il a créé Banana RDF, une bibliothèque Scala issue du projet read-write-web mené pour Tim Berners-Lee. Chez Apple, il a déployé le graphe de connaissances marketing et retail d'Apple sur apple.com avec schema.org, avec un impact SEO significatif, et a représenté Apple au sein du Schema.org Community Group. Il a ensuite été data engineer sur la plateforme anti-fraude d'Apple Services, puis a dirigé une équipe d'ingénieurs pour migrer l'infrastructure d'Apple Media Services vers Kubernetes.