Conference45min
Production Troubleshooting : boostez vos skills, une étude de cas
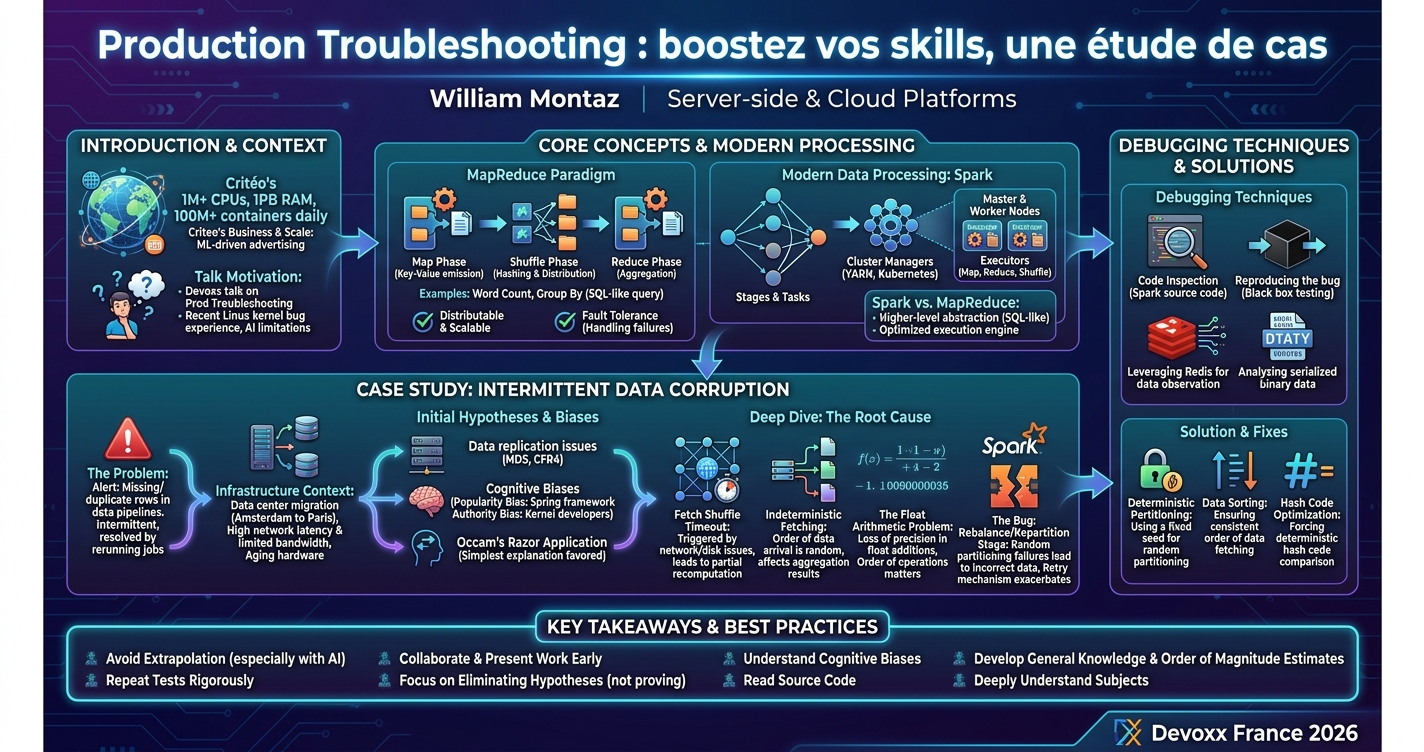
À partir d’un incident réel impliquant des jobs Spark corrompant des données, cette session explore une méthode rigoureuse d’investigation technique : formuler et tester des hypothèses, éviter les biais, distinguer corrélation et cause réelle. Objectif : apprendre à diagnostiquer efficacement tout incident complexe, même en environnement incertain.
talk.summaryAiDisclaimer

William MontazCriteo
talkDetail.whenAndWhere
Wednesday, April 22, 11:35-12:20
Paris 143
Quand un incident critique survient, la pression monte immédiatement: données incohérentes, comportements imprévisibles, utilisateurs en alerte. Le réflexe naturel ? Chercher un coupable évident, pointer du doigt le dernier changement effectué, ou se laisser guider par l'intuition... sans progresser.
Dans cette session, je vous propose une exploration guidée d'une enquête technique réelle. Spark apparaît dans l'histoire, mais il n'est qu'un prétexte : le vrai sujet, c'est la méthode. Comment diagnostiquer un problème complexe sans s'éparpiller ? Comment éviter le biais de confirmation qui sabote nos investigations ? Comment découper progressivement un incident obscur en hypothèses claires et testables ?
Le cas concret ? Des jobs Spark qui produisent de la data corrompue, avec des lignes en doublon et d'autres manquantes, en pleine migration de datacenter forcément. En revivant cet incident, vous découvrirez comment :
- Construire une investigation pas-à-pas, même en terrain inconnu
- Éliminer les mauvaises pistes
- Vérifier les hypothèses de façon méthodique
- Distinguer corrélation, coïncidence et véritable root cause
...et ce qui s'est vraiment passé !
Dans cette session, je vous propose une exploration guidée d'une enquête technique réelle. Spark apparaît dans l'histoire, mais il n'est qu'un prétexte : le vrai sujet, c'est la méthode. Comment diagnostiquer un problème complexe sans s'éparpiller ? Comment éviter le biais de confirmation qui sabote nos investigations ? Comment découper progressivement un incident obscur en hypothèses claires et testables ?
Le cas concret ? Des jobs Spark qui produisent de la data corrompue, avec des lignes en doublon et d'autres manquantes, en pleine migration de datacenter forcément. En revivant cet incident, vous découvrirez comment :
- Construire une investigation pas-à-pas, même en terrain inconnu
- Éliminer les mauvaises pistes
- Vérifier les hypothèses de façon méthodique
- Distinguer corrélation, coïncidence et véritable root cause
...et ce qui s'est vraiment passé !
William Montaz
Je suis SRE à Criteo depuis plus de 8 ans, en charge de la production de la plateforme offline (hadoop) et des systèmes de stockage distribués (HDFS, Ceph).
Cette experience dans la durée m'a offert une experience riche, sur le scale (de 1000 à 3800 serveurs sur la stack Hadoop), l'intégration de plusieurs plateformes de conteneurs majeures (Yarn, Mesos et Kubernetes), ouverture et migration live de plusieurs datacenters, et transformation progressive du SI Criteo en cloud on-premise.
Cette experience dans la durée m'a offert une experience riche, sur le scale (de 1000 à 3800 serveurs sur la stack Hadoop), l'intégration de plusieurs plateformes de conteneurs majeures (Yarn, Mesos et Kubernetes), ouverture et migration live de plusieurs datacenters, et transformation progressive du SI Criteo en cloud on-premise.