Conference45min
Et si on ouvrait le capot de PostgreSQL ?
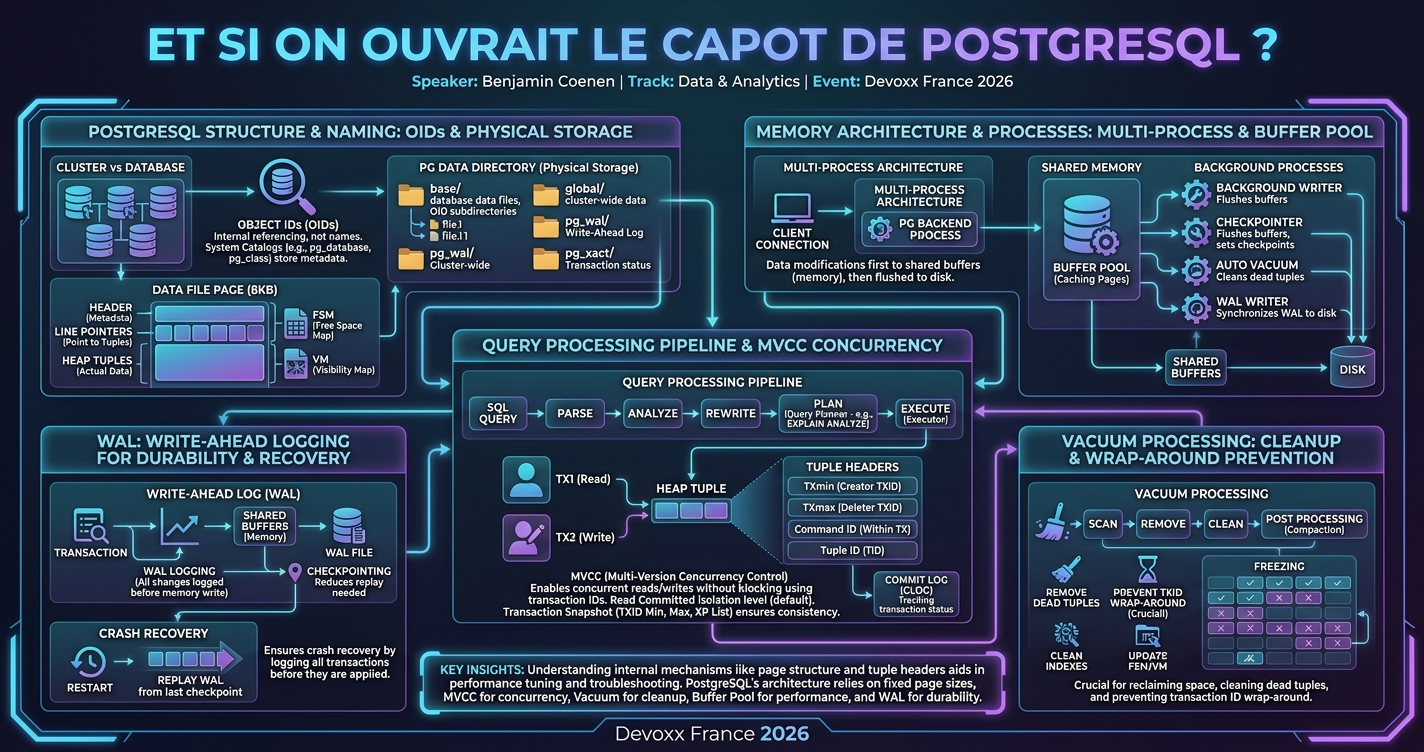
PostgreSQL est une des bases de données les plus utilisées et les plus appréciées. Mais sait-on vraiment comment elle fonctionne ? Qu’est ce qui lui permet d’être à la fois performante, tolérante aux crashs et hautement disponible ? Je vous propose de découvrir ensemble les internals de Postgres et d'apprendre comment sont stockées vos données sur celle-ci. En partant d’une simple requête sql et en passant par toutes les étapes pour récupérer la donnée que l'on recherche, découvrons comment PG fonctionne. Nous aborderons les notions spécifiques aux implémentations de bases de données et plus spécifiquement celles de Postgres (query planner, write ahead log, mvcc, tuples, vacuum, …).
talk.summaryAiDisclaimer

Benjamin CoenenSupabase
talkDetail.whenAndWhere
Friday, April 24, 10:30-11:15
Neuilly 252AB
PostgreSQL est une des bases de données les plus utilisées et les plus appréciées. Mais sait-on vraiment comment elle fonctionne ?
Qu’est ce qui lui permet d’être à la fois performante, tolérante aux crashs et hautement disponible ?
Je vous propose de découvrir ensemble les internals de Postgres et d'apprendre comment sont stockées vos données sur celle-ci.
En partant d’une simple requête sql et en passant par toutes les étapes pour récupérer la donnée que l'on recherche, découvrons comment PG fonctionne.
Nous aborderons les notions spécifiques aux implémentations de bases de données et plus spécifiquement celles de Postgres (query planner, write ahead log, mvcc, tuples, vacuum, …).
Qu’est ce qui lui permet d’être à la fois performante, tolérante aux crashs et hautement disponible ?
Je vous propose de découvrir ensemble les internals de Postgres et d'apprendre comment sont stockées vos données sur celle-ci.
En partant d’une simple requête sql et en passant par toutes les étapes pour récupérer la donnée que l'on recherche, découvrons comment PG fonctionne.
Nous aborderons les notions spécifiques aux implémentations de bases de données et plus spécifiquement celles de Postgres (query planner, write ahead log, mvcc, tuples, vacuum, …).
Benjamin Coenen
Software engineer @ Supabase
Je suis tombé amoureux du développement informatique en écrivant de l'assembleur sur des microcontrôleurs. J'ai toujours principalement travailler autour des dev tools. Toujours en recherche de comprendre ce qu'il se passe sous le capot je passe une bonne partie de mon temps à écrire du Rust et optimiser les performances de mon code. "Opensource everything" est mon mantra. J'adore partager et contribuer dans la communauté tech et open source. J'ai notamment beaucoup contribué à Rust analyzer qui est le LSP (language server protocol) officiel de Rust. Chez Apollo GraphQL, j'ai développé un runtime en Rust (le Router) qui permet d'exécuter du GraphQL (Federation) en mode micro service. Aujourd'hui je suis chez supabase et travaille principalement sur https://github.com/supabase/etl . Je contribue aussi activement à l'éditeur de code Zed.
Je suis tombé amoureux du développement informatique en écrivant de l'assembleur sur des microcontrôleurs. J'ai toujours principalement travailler autour des dev tools. Toujours en recherche de comprendre ce qu'il se passe sous le capot je passe une bonne partie de mon temps à écrire du Rust et optimiser les performances de mon code. "Opensource everything" est mon mantra. J'adore partager et contribuer dans la communauté tech et open source. J'ai notamment beaucoup contribué à Rust analyzer qui est le LSP (language server protocol) officiel de Rust. Chez Apollo GraphQL, j'ai développé un runtime en Rust (le Router) qui permet d'exécuter du GraphQL (Federation) en mode micro service. Aujourd'hui je suis chez supabase et travaille principalement sur https://github.com/supabase/etl . Je contribue aussi activement à l'éditeur de code Zed.