Conference50min
Fast, Cheap, and Accurate: Optimizing LLM Inference with vLLM and Quantization
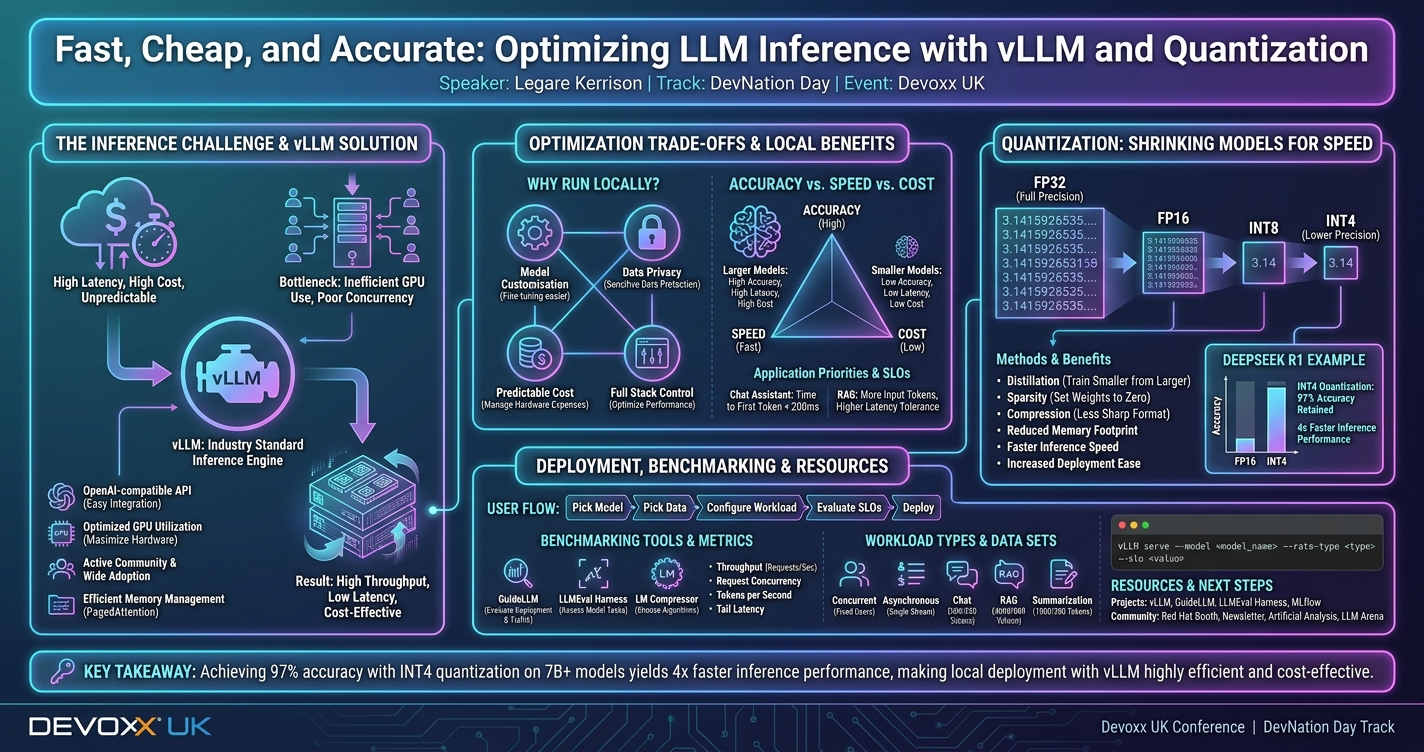
This demo-driven talk shows how to efficiently serve large language models using vLLM, focusing on optimizing latency, throughput, and memory. It compares standard and quantized models under load, explains practical tuning, and equips attendees with actionable methods to evaluate and improve inference performance for real-world AI applications.
talk.summaryAiDisclaimer

Legare KerrisonRed Hat
talkDetail.whenAndWhere
Thursday, May 7, 09:00-09:50
Room E
Generative AI models are impressive, but the moment you try to run one behind a real app, the bill (and the latency) can get out of hand. A lot of that comes down to inference: what you serve the model on, how well it uses GPU memory, and how it behaves when multiple requests hit at once.
This talk is a demo-driven walkthrough of serving LLMs efficiently with vLLM, an open source inference engine that exposes an OpenAI-compatible API—so you can wire it into an app without inventing a new protocol. We’ll start by serving a baseline model and driving traffic from a simple client while watching the numbers that matter: latency (including tail latency), throughput, and memory use.
Then we’ll change one thing: we’ll swap in quantized versions of the same model. You’ll see what improves, what doesn’t, and where the trade-offs show up in practice. We’ll repeat the exact same workload so it’s obvious what changed and why, and we’ll cover a few practical tuning knobs in vLLM that can make or break performance under load.
You’ll walk away with a clear mental model of “efficient inference,” a repeatable way to test your own setup, and a pragmatic sense of when quantization is the right move for your app—without needing an ML background.
This talk is a demo-driven walkthrough of serving LLMs efficiently with vLLM, an open source inference engine that exposes an OpenAI-compatible API—so you can wire it into an app without inventing a new protocol. We’ll start by serving a baseline model and driving traffic from a simple client while watching the numbers that matter: latency (including tail latency), throughput, and memory use.
Then we’ll change one thing: we’ll swap in quantized versions of the same model. You’ll see what improves, what doesn’t, and where the trade-offs show up in practice. We’ll repeat the exact same workload so it’s obvious what changed and why, and we’ll cover a few practical tuning knobs in vLLM that can make or break performance under load.
You’ll walk away with a clear mental model of “efficient inference,” a repeatable way to test your own setup, and a pragmatic sense of when quantization is the right move for your app—without needing an ML background.
Legare Kerrison
Legare Kerrison is an Open Source Engineer and Developer Advocate on Red Hat's AI team. She focuses on open source tools for building and deploying AI. Currently, she works with projects like vLLM and Podman desktop. She aims to make technical complexity digestible. She loves matcha and the outdoors. Based in Boston.