Architecture
ArchitectureDeep Dive180min
Large Scale Distributed LLM Inference with LLM-D and Kubernetes
This session introduces LLM-D, a Kubernetes-based distributed framework for scalable, cost-efficient LLM inference. Addressing challenges like accelerator scarcity and deployment complexity, LLM-D offers optimized architecture and components—leveraging technologies like vLLM and Prometheus—to enable high-performance, operational GenAI deployments across diverse hardware, designed by major industry contributors.
talk.summaryAiDisclaimer

Abdel SghiouarGoogle Cloud
talkDetail.whenAndWhere
Monday, October 6, 13:30-16:30
Room 9
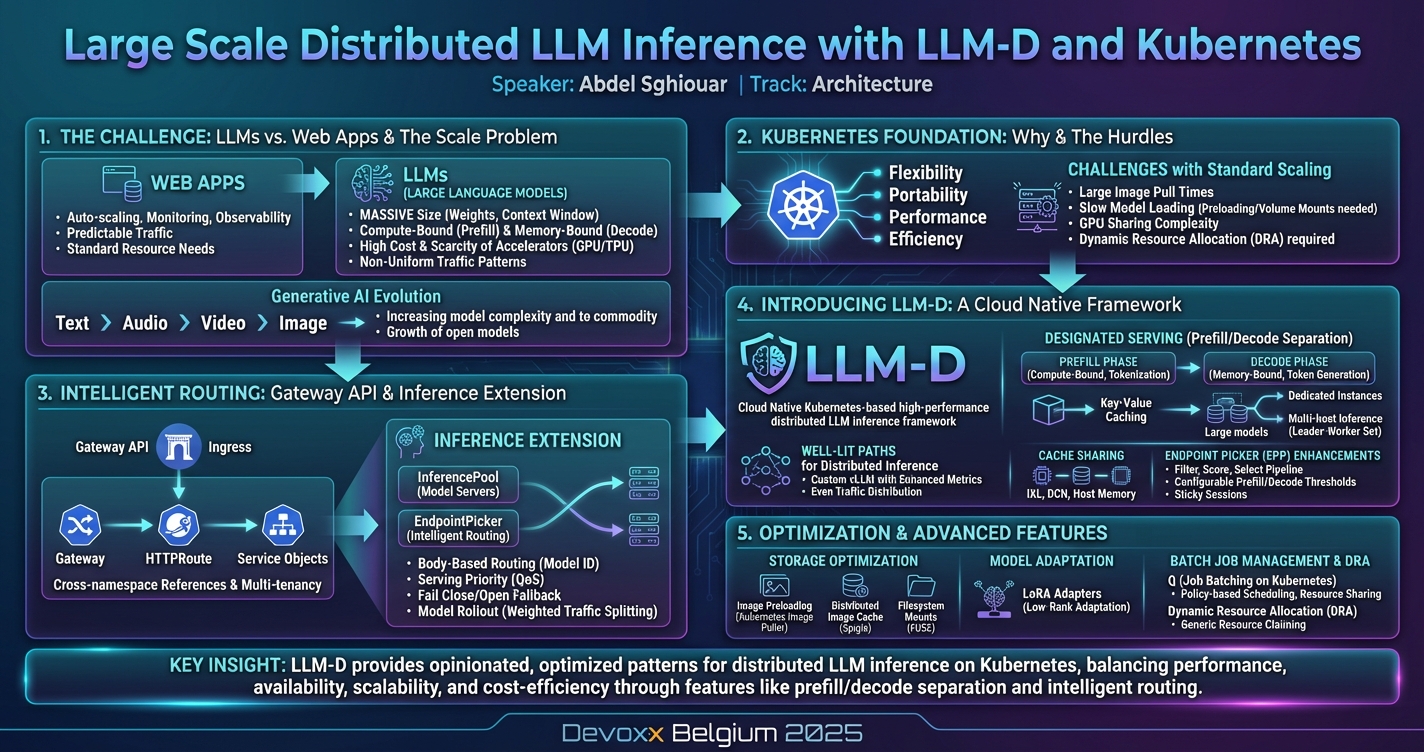
Running Large Language Models (LLMs) locally for experimentation is easy but running them in large scale architectures is not. It requires businesses looking to intergate LLMs into their critical paths to deal with the high costs and scarcity of GPU/TPU accelerators present a significant challenge. Striking the balance between performance, availability, scalability, and cost-efficiency is a must.
While Kubernetes is a ubiquitous runtime for modern workloads, deploying LLM inference effectively demands a specialized approach. Enter LLM-D a Cloud Native Kubernetes based high-performance distributed LLM inference framework. It's architecture centers around a well-lit path for anyone looking to serve at scale, with the fastest time-to-value and competitive performance per dollar, for most models across a diverse and comprehensive set of hardware accelerators.
In this deep dive we will start with a gentle introduction to the topic of Inference on Kubernetes and slowly work our way to why LLM-D and what kind of challenges it solves. LLM-D is a set of components and an opinionated architecture. Building on top of existing projects like vLLM, Prometheus, the Kubernetes Gateway API. It's optimized KV-cache aware routing and disaggregated serving are designed to operationalize GenAI deployments. The project was designed by the creators of vLLM (Redhat, Google, Bytedance) and it's licensed under the Apache 2 License.
While Kubernetes is a ubiquitous runtime for modern workloads, deploying LLM inference effectively demands a specialized approach. Enter LLM-D a Cloud Native Kubernetes based high-performance distributed LLM inference framework. It's architecture centers around a well-lit path for anyone looking to serve at scale, with the fastest time-to-value and competitive performance per dollar, for most models across a diverse and comprehensive set of hardware accelerators.
In this deep dive we will start with a gentle introduction to the topic of Inference on Kubernetes and slowly work our way to why LLM-D and what kind of challenges it solves. LLM-D is a set of components and an opinionated architecture. Building on top of existing projects like vLLM, Prometheus, the Kubernetes Gateway API. It's optimized KV-cache aware routing and disaggregated serving are designed to operationalize GenAI deployments. The project was designed by the creators of vLLM (Redhat, Google, Bytedance) and it's licensed under the Apache 2 License.
Abdel Sghiouar
Abdel Sghiouar is a senior Developer @Google Cloud. A co-host of the Kubernetes Podcast by Google and a CNCF Ambassador. His focused areas are High Scale distributed systems on Kubernetes, Service Mesh, and Serverless. With a background in datacenter scale architecture and operations and consulting. He spends most of his time working on optimizing GenAI Apps for large scale operations using Cloud Native Technologies and producing content targeting developers and ops professionals.