GenAI & Beyond
GenAI & BeyondConference50min
GPULlama3.java: Beyond CPU Inference with Modern Java
This session introduces GPULlama3.java, an open-source framework enabling efficient, GPU-accelerated inference for Llama and similar models directly in Java using TornadoVM. Attendees will learn about Java-native LLM support, GPU optimization, and integration with LangChain4j, with a live demo on diverse hardware and profiling tools.
talk.summaryAiDisclaimer

Michalis PapadimitriouUniversity of Manchester
talkDetail.whenAndWhere
Thursday, October 9, 17:40-18:30
Room 6
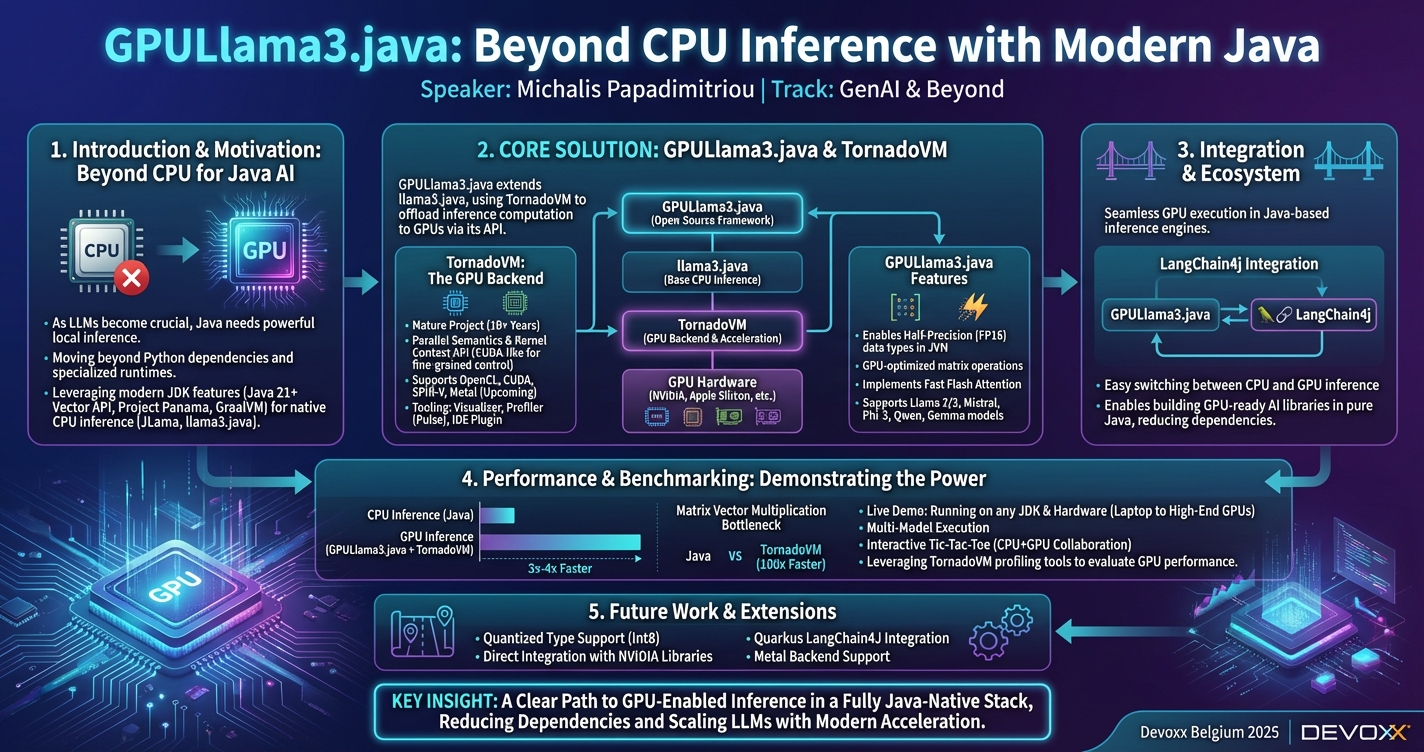
As Large Language Models (LLMs) become crucial to AI applications, Java developers are now equipped to run powerful local inference using modern JDK features without relying on Python or specialized runtimes. Thanks to Java 21+'s Vector API and projects like JLama and llama3.java, the JVM ecosystem now supports efficient, native CPU inference for popular open-source models like Llama 2/3, Gemma, and Mistral. At the same time, GPU computing for Java is reaching new maturity with TornadoVM.
This session introduces GPULlama3.java, an open-source framework built on top of llama3.java, which uses TornadoVM to offload inference computation to GPUs, just by leveraging its API. GPULlama3 showcases how to enable half-precision data types in the JVM, express GPU-optimized matrix operations, implement fast Flash Attention, and ensure compatibility with Llama 2/3 and Mistral models. Moreover, demonstrates integration with LangChain4j for seamless GPU execution in Java-based inference engines.
Finally, the session will include a live demo showing how GPULlama3.java can run on any JDK and hardware ranging from Apple Silicon to high-end NVIDIA GPUs. Also, explores how to leverage TornadoVM’s profiling and analysis tools to evaluate GPU performance during inference.
Whether you're building AI apps on the JVM or looking to scale LLMs on Java with modern acceleration, this session will give you a clear path to GPU-enabled inference in a fully Java-native stack.
This session introduces GPULlama3.java, an open-source framework built on top of llama3.java, which uses TornadoVM to offload inference computation to GPUs, just by leveraging its API. GPULlama3 showcases how to enable half-precision data types in the JVM, express GPU-optimized matrix operations, implement fast Flash Attention, and ensure compatibility with Llama 2/3 and Mistral models. Moreover, demonstrates integration with LangChain4j for seamless GPU execution in Java-based inference engines.
Finally, the session will include a live demo showing how GPULlama3.java can run on any JDK and hardware ranging from Apple Silicon to high-end NVIDIA GPUs. Also, explores how to leverage TornadoVM’s profiling and analysis tools to evaluate GPU performance during inference.
Whether you're building AI apps on the JVM or looking to scale LLMs on Java with modern acceleration, this session will give you a clear path to GPU-enabled inference in a fully Java-native stack.
Michalis Papadimitriou
Michalis Papadimitriou is a Research Fellow at the University of Manchester and a Staff Software Engineer on the TornadoVM team. His core expertise includes open-source software development, hardware abstractions for high-level programming languages, compiler optimizations for GPU computing, and enabling large language model (LLM) inference on GPUs for the Java Virtual Machine (JVM).
Michalis is focused on advancing GPU acceleration for machine learning workloads on the JVM through the TornadoVM framework and actively maintains the GPULlama3.java project.
Before joining the University of Manchester, he worked on a range of software stacks at Huawei Technologies and contributed to the open-source machine learning compiler Apache TVM, while working for OctoAI (formerly OctoML), which was later acquired by Nvidia.
Michalis is focused on advancing GPU acceleration for machine learning workloads on the JVM through the TornadoVM framework and actively maintains the GPULlama3.java project.
Before joining the University of Manchester, he worked on a range of software stacks at Huawei Technologies and contributed to the open-source machine learning compiler Apache TVM, while working for OctoAI (formerly OctoML), which was later acquired by Nvidia.