Data & AI
Data & AIConference40min
Apache Spark Declarative Pipelines in Action: Lessons from Processing Live Aircraft Data at Global Scale
This session introduces Spark Declarative Pipelines (SDP) in Apache Spark 4.1, demonstrating streamlined, declarative data pipeline creation using live avionics data. Attendees learn SDP fundamentals, hands-on pipeline building, AI integration for NLP queries, and best practices—all replicable on a free lakehouse platform with open-source tools.
talk.summaryAiDisclaimer

Frank MunzDatabricks
talkDetail.whenAndWhere
Saturday, April 25, 14:20-15:00
MC 2
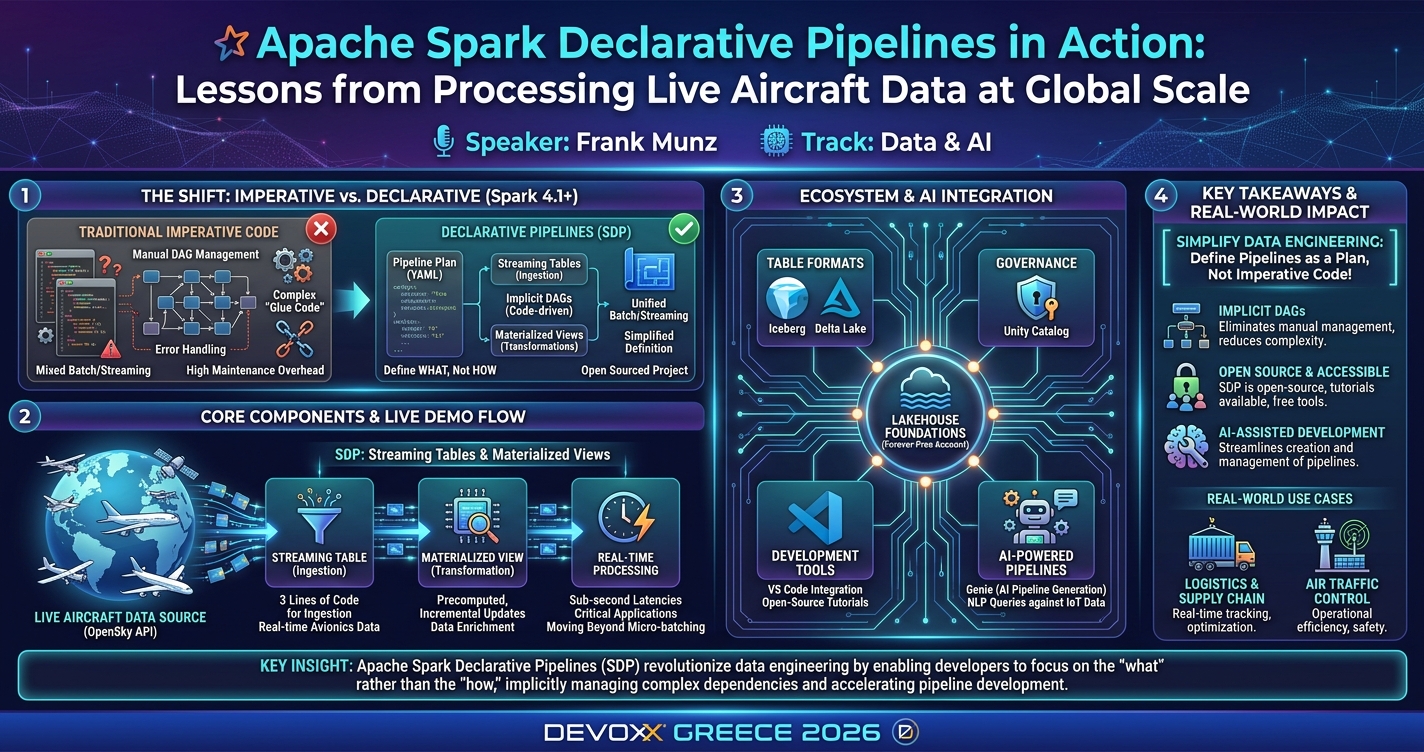
Apache Spark 4.1, released in December 2025, introduces Spark Declarative Pipelines (SDP), a paradigm shift that transforms how data engineers design and maintain complex data pipelines. This hands-on session provides a critical review of SDP's design decisions and comprehensive introduction, demonstrating how declarative pipelines replace traditional imperative Spark code.
We'll build a live data pipeline processing real avionics data streamed from tens of thousands of aircraft—from tiny Cessnas to massive Airbus A380s—flying overhead right now. This demo uses an open-sourced PySpark data source I developed with OpenSky founders from Oxford and ETH Zurich, enabling direct access to live ADS-B flight telemetry.
We'll create pipelines using SDP's streaming tables for ingestion and materialized views for transformations—all in declarative configuration. No complex "glue code"—just define what your pipeline should accomplish. The demo runs on a forever-free Lakehouse account implementing all OSS lakehouse foundations: table formats (Iceberg and Delta), governance with Unity Catalog, and Apache Spark with SDP.
As icing on the cake, I'll show AI integration for NLP queries against live IoT data. Attendees can replicate everything at no cost.
You'll leave with practical SDP knowledge and best practices for pipeline modernization. WARNING: After this breakout session, you may catch the virus of tracking live aircraft data—don't worry, the data pipeline won't be your bottleneck!
We'll build a live data pipeline processing real avionics data streamed from tens of thousands of aircraft—from tiny Cessnas to massive Airbus A380s—flying overhead right now. This demo uses an open-sourced PySpark data source I developed with OpenSky founders from Oxford and ETH Zurich, enabling direct access to live ADS-B flight telemetry.
We'll create pipelines using SDP's streaming tables for ingestion and materialized views for transformations—all in declarative configuration. No complex "glue code"—just define what your pipeline should accomplish. The demo runs on a forever-free Lakehouse account implementing all OSS lakehouse foundations: table formats (Iceberg and Delta), governance with Unity Catalog, and Apache Spark with SDP.
As icing on the cake, I'll show AI integration for NLP queries against live IoT data. Attendees can replicate everything at no cost.
You'll leave with practical SDP knowledge and best practices for pipeline modernization. WARNING: After this breakout session, you may catch the virus of tracking live aircraft data—don't worry, the data pipeline won't be your bottleneck!
Frank Munz
Frank Munz solves large-scale data and AI challenges at Databricks. He authored three computer science books, established technical evangelism for Amazon Web Services in Germany, Austria, and Switzerland, and once worked as a data scientist with a group that won a Nobel Prize.
Frank has presented at top-notch conferences on every continent (except Antarctica, due to its inhospitable climate). His speaking engagements include re:Invent, Devoxx, KubeCon, and JavaOne. He is also a 3x published author.
He is renowned for his world-class demos, which often showcase innovative and interactive applications of technology.
He holds a Ph.D. with summa cum laude in Computer Science from TU Munich, where he worked on supercomputing and brain research.
Frank has presented at top-notch conferences on every continent (except Antarctica, due to its inhospitable climate). His speaking engagements include re:Invent, Devoxx, KubeCon, and JavaOne. He is also a 3x published author.
He is renowned for his world-class demos, which often showcase innovative and interactive applications of technology.
He holds a Ph.D. with summa cum laude in Computer Science from TU Munich, where he worked on supercomputing and brain research.