Data & AI
Data & AIConference40min
The GPU Orchestration Playbook: AI Inference at Scale
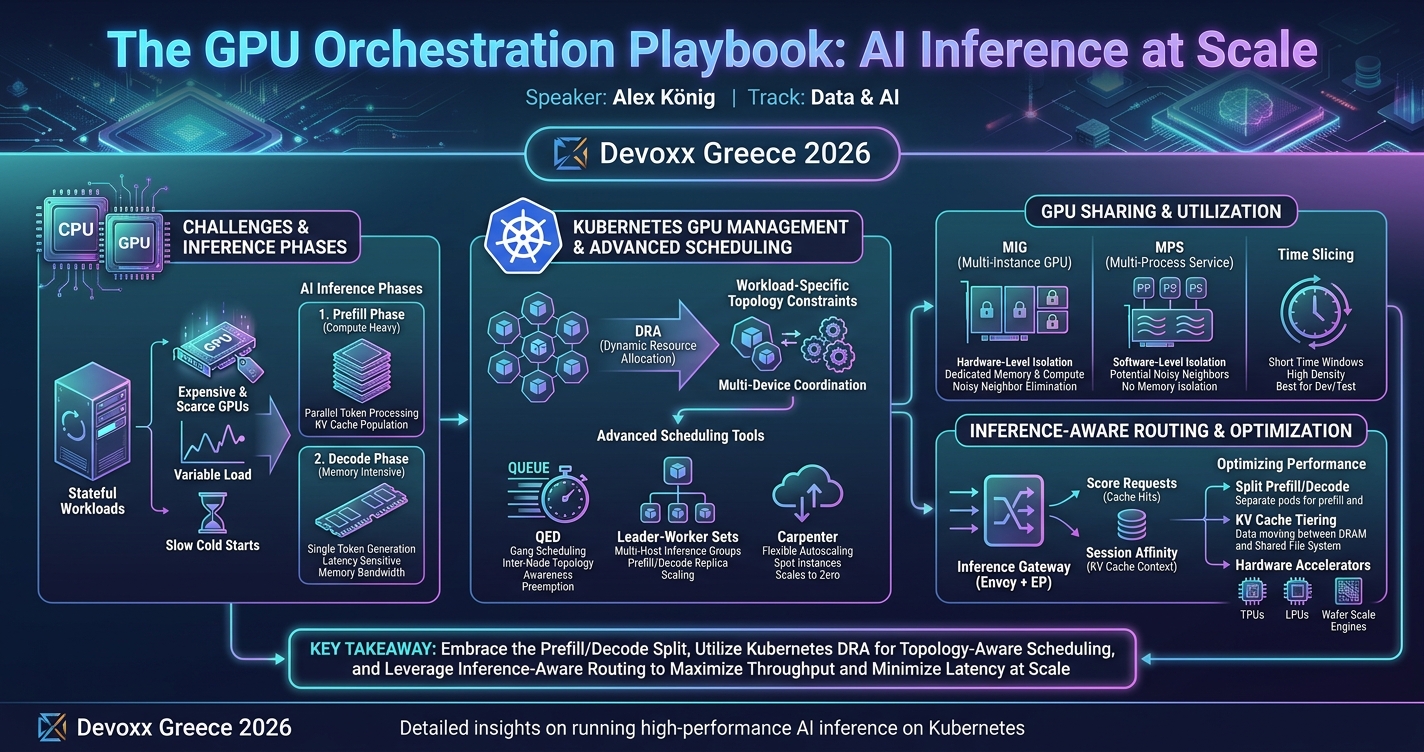
This session covers best practices for deploying large AI models on Kubernetes, focusing on GPU orchestration, advanced scheduling, autoscaling, and storage strategies to optimize inference performance. Attendees will gain practical insights for reliably running scalable AI workloads in production across cloud-native environments.
talk.summaryAiDisclaimer

Alex KönigAWS
talkDetail.whenAndWhere
Saturday, April 25, 11:25-12:05
Banquet
As AI workloads scale, serving large models reliably and efficiently has become a central challenge for engineering teams. In this session, we explore patterns and best practices for running high-performance AI inference on Kubernetes. Attendees will learn about GPU orchestration, advanced scheduling, autoscaling strategies and architectural decisions that minimize latency and maximize throughput. We’ll also cover storage considerations and practical approaches to deploying models in production. This talk is ideal for engineers and platform teams who want to understand how to operate AI workloads at scale while maintaining reliability and performance across cloud-native environments.
Alex König
Alex is a Senior Solutions Architect at AWS. He is experienced in large scale and distributed architectures, Kubernetes, Open Source, DevOps, automation and emerging technologies. He has given talks and written blogs about software architecture, Kubernetes and AI. With a background as a systems engineer he still likes to write shell scripts.